
Robots.txt là một trong những file quan trọng nhất với một web chuẩn SEO. Việt thiết lập file này ảnh hưởng trực tiếp tới quá trình SEO. Cùng tìm hiểu về Robots và cách thiết lập quy chuẩn
Tóm tắt nội dung
Robots.txt là gì
Robots.txt là file văn bản lưu trữ text đơn giản có định dạng đuôi .txt, chứa thông tin câu lệnh: cho phép hoặc cấm các bọ tìm kiếm index trang web. Robots.txt được upload trực tiếp lên Files của tên miền gốc.
Mỗi một Tên miền chỉ có 1 file Robots.txt duy nhất, có dạng: tenmien.vn/robots.txt và tên file này là cố định, tên nó phải là: robots.txt chứ không thể là: robot.txt hay robotxyz.txt – hãy nhớ điều này.
Trước hết, hãy xem file Robots của web kinh điển: google.com/robots.txt – đúng, cái bạn đang thấy là file Robots của Google đấy! Còn đây là của chúng tôi, đơn giản hơn nhiều: seomax.net/robots.txt bạn có rút ra được điều gì không? Nếu hiểu rồi thì tốt, không hãy xem phần sau nhé.
File Robots.txt gồm các dòng text đơn giản như sau:
|
1 2 3 4 5 6 7 |
User-agent: * Disallow: /url-khong-index/ Disallow: /nhieu-url-khong-index/* Allow: /url-index/ Allow: /nhom-url-index/* Sitemap: https://tenmien.vn/sitemap.xml |
Trong đó ta chỉ cần quan tâm câu 4 lệnh:
- User-agent: Cho phép các bọ tìm kiếm index nội dung trang web.
- Disallow: KHÔNG cho phép đánh chỉ mục URL, nhóm URL này
- Allow: Cho phép Google đánh chỉ mục, Crawl nội dung URL này (tác dụng với Googlebot)
- Sitemap: Sơ đồ trang web chính thức (tác dụng với bot của Google, Ask, Bing và Yahoo)
- Dấu * sau User-agent: Lệnh chung áp dụng cho tất cả các bot (Google, Cốc Cốc, Bing,…)
- Dấu * sau Allow/Disallow: nhóm url khác nhau sau dấu gạch chéo /nhu-nhau/khac-nhau
Xem thêm: Robots.txt quy chuẩn của Google
Robots trong SEO
Robots.txt là file quan trọng nhất với một website để xét tiêu chuẩn đủ điều kiện SEO hay không. Chưa cần biết web bạn có nội dung gì, tối ưu chuẩn SEO đến đâu mà Robots sai thì đời kiếp này đừng mong Google yêu.
Đã là SEOer điều bắt buộc phải biết: Tạo file robots, đọc tệp robots và sửa file robots chuẩn SEO.
Vai trò file Robots.txt
- Điều hướng bot tìm kiếm đánh chỉ mục một trang web
- Hướng dẫn SES thông tin được chia sẻ của trang web
- Ngăn chặn một URL xuất hiện trên trang tìm kiếm (Google, Bing,…)
- Xóa bỏ toàn bộ kết quả SEO của một website đã top
- Chỉ dẫn bọ tìm kiếm đến Sitemap chính thống web đang dùng
Robots có điểm hay ở chỗ: lệnh đúng thì thực hiện, lệnh sai thì nó bỏ qua và mặc định lệnh sai đó tức là vẫn index. Bạn gõ sai lệnh không quan trọng, nhưng lệnh đúng mà URL sai thì xong luôn đấy!
Robots.txt & Meta robots
Cần phân biệt được Tệp Robots.txt và Thẻ Meta Robots tag vì đây là vấn đề sống còn trong SEO. Hiểu và áp dụng đúng thì SEO tốt, áp dụng sai nên viết đơn nghỉ việc và chuẩn bị tiền đền bù c.ty 🙂
#1. File Robots
File Robots.txt có ảnh hưởng tới toàn bộ website, lệnh thực thi trong file này có tác dụng với toàn bộ trang web.
|
1 2 3 |
User-agent: * Allow: / Disallow: / |
#2. Meta Robots
Thẻ Meta Robots tag chỉ có ảnh hưởng tới 1 URL duy nhất trong web. VD bạn không muốn Google index nội dung đã cũ, hoặc trang 404 Error thì dùng thẻ meta tag này.
|
1 |
<meta name="robots" content="noindex,follow"/> |
Các tay SEO gà mờ không nên sờ đến và chỉnh sửa 2 loại lệnh này, báo coder kiểm tra nếu có nghi ngờ nhé. Xin nhắc lại, dùng sai 1 trong 2 loại Robots trên bạn đều tự tay xóa xổ mình khỏi Google – đừng dại.
Dùng Robots như thế nào
Các web chuẩn SEO bắt buộc có file này, hãy tạo robots.txt rồi upload trực tiếp Files mã nguồn tên miền gốc. Tức là nó nằm trực tiếp trong Folder gốc của web, trong Hosting. VD như dùng Cpanel quản trị files, bạn sẽ thấy robots như thế này:
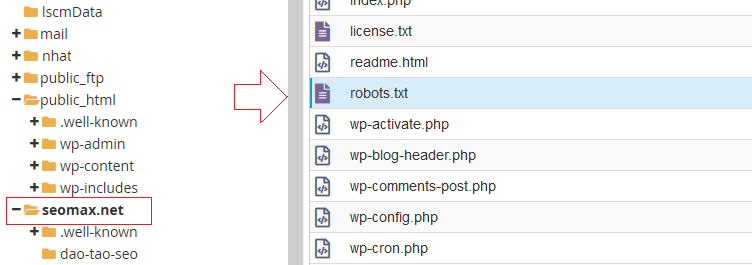
Nếu không rành, hãy nhờ người code web upload lên thay bạn, đừng làm sai bất kỳ bước nào với file này. Dùng file Robots nên cẩn trọng, sử dụng nó trong các trường hợp như sau:
- Muốn chặn không cho các bot index nội dung thừa, web bí mật
- Chặn nội dung không cần thiết index như trang quản trị /wp-admin/
- Chặn các thông số thừa trong URL mà web tự tạo, VD: Disallow: /?orderby=*
- Đưa ra sơ đồ trang web định dạng XML chuẩn cho bot crawl
Nó nguy hiểm vậy liệu Website cần file Robots này không? xin thưa là CÓ! Rất cần.
Cách tạo Robots.txt
Tạo tệp robot.txt rất đơn giản, bạn chỉ cần thao tác theo các bước sau
- Bước 1: Mở ứng dụng Notepad trong Windows, hoặc tạo tệp .txt online ở ĐÂY -> lưu về máy
- Bước 2: Điền thông tin, câu lệnh cho file robots.txt. Xem: hướng dẫn Robots chuẩn của Google
- Bước 3: Upload tệp robots.txt vào thư mục gốc của Tên miền – trong hosting.
Quy tắc chung: Đây là file robots đơn giản nhất, tùy vào mỗi web để bạn thiết lập. Các câu lệnh như đã nói ở phần File Robots là gì. Tạo file có nội dung như sau rồi lưu lại định dạng .txt
|
1 2 3 4 |
User-agent: * Disallow: /url-admin/ Sitemap: https://tenmien.vn/sitemap.xml |
Lưu ý: Một số bạn hay để thêm lệnh Allow: / trong file robots – Điều này là KHÔNG cần thiết. Cứ không có Disallow: thì tức là đã tự động Allow: rồi.
Allow và Disallow cùng nhau
Các bọ tìm kiếm hiểu và cho phép bạn chặn index URL mẹ nhưng vẫn có thể index URL con. Trường hợp này thường dùng cho việc chặn Danh mục bí mật nào đó, nhưng lại muốn bot crawl một vài link.
Xem ví dụ tệp robots sau:
|
1 2 3 |
User-agent: * Disallow: /phim-18/ Allow: /phim-18/tram-anh.html |
Có nghĩa là: không index toàn bộ mục /phim-18/nhưng lại cho phép index 1 url /phim-18/tram-anh.html
Kiểm tra file Robots.txt
Cách kiểm tra tệp robots đã hoạt động hay chưa rất đơn giản, chỉ cần vào đường dẫn cố định xem có nội dung chưa là được: https://tenmien.vn/robots.txt
Lưu ý: Thay tenmien.vn bằng Domain của bạn nhé. VD của mình là https://seomax.net/robots.txt
Kiểm tra thủ công thì như trên, còn với một SEOer cần phải check kỹ trong Search Console xem hoạt động của lệnh robots này như thế nào, có chặn nhầm URL nào không? Hướng dẫn kiểm tra robots của Google
Sau khi hoàn thiện một website, muốn Google sớm index nội dung bạn cần tạo file Robots.txt. Sau khi upload lên host thì kiểm tra thật kỹ: Đầu tiên là bằng mắt thường, sau đó là vào Search Console để test kỹ – mất thời gian cũng được nhưng đừng sai lầm file này!
Robots.txt cho WordPress
WordPress có rất nhiều cách tạo robots.txt mà không cần can thiệp trực tiếp vào hosting. Có thể dùng Yoast SEO hoặc cài Plugin Virtual Robots.txt chỉ với 1 click là xong.
Mẫu file robots.txt cho WP cơ bản có Yoast SEO
|
1 2 3 4 5 6 7 |
User-agent: * Disallow: /wp-admin/ Disallow: /*?*p= Disallow: /*?*ver= Allow: /wp-admin/admin-ajax.php Sitemap: https://tenmien/sitemap_index.xml |
Mẫu file robots.txt cho WP có Woocommerce
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
User-agent: * Disallow: /wp-admin/ Disallow: /cart/ Disallow: /my-account/ Disallow: /wishlist/ Disallow: /order-tracking/ Disallow: /checkout/ Disallow: /*?*filter_ten-bo-loc= Disallow: /*?*min_price= Disallow: /*?*max_price= Disallow: /*?*orderby= Allow: /wp-admin/admin-ajax.php Sitemap: https://tenmien.vn/sitemap_index.xml |
Phần /*?*filter_ten-bo-loc= là Thuộc tính sản phẩm của Woo (Products Attributes filter) – nên chặn index phần này. Tùy mỗi web mà ứng dụng linh hoạt, nhớ đừng chặn nhầm URL cần SEO đấy!
Lưu ý: Tạo SP có thuộc tính trong Woo phát sinh URL có thêm /?filter_, Ví dụ: /?filter_chon-mau-sac= mà Google vẫn index link. Nếu có thẻ Canonical rồi không sao, nếu không có thì đúng là thảm họa SEO. Tốt nhất, nên dùng Robots.txt chặn link phát sinh của phần lọc thuộc tính này lại.
Mẫu tệp robots.txt với Mythemeshop + Woo
Mythemeshop cung cấp các loại theme WP chuẩn SEO nhất hiện nay, nhưng họ dính 1 lỗi nhỏ trong phần giỏ hàng: Tự tạo URL riêng cho mỗi lần đặt hàng?? Không hiểu vì sao luôn?? Vậy nên nếu sử dụng Mythemeshop + Woo cần thêm dòng sau vào file Robot (còn lại các lệnh như phần WP + Woo trên)
|
1 |
Disallow: /*?*add-to-cart= |

Lưu ý quan trọng
Bất kỳ quy tắc nào trong robots.txt là chỉ thị. Điều này có nghĩa: Công cụ tìm kiếm phải tuân theo và thực hiện đúng các lệnh bạn đã đưa vào. Chỉ nên dùng 3 lệnh: User-agent: * Disallow: và Allow:
Việc thực thi tệp robots.txt và Meta robots tag có thể diễn ra đồng thời, nhưng bot SES chỉ thực hiện lệnh trong Meta robots khi mà KHÔNG có trong robots.txt. Nếu có đồng thời lệnh như nhau thì các bot chỉ thực thi lệnh từ robots.txt (bỏ qua thẻ tag meta name=”robots”)
Câu hỏi thường gặp
Nếu web không có file robots? Thì bọ tìm kiếm sẽ đánh chỉ mục, thu thập dữ liệu toàn bộ 100% nội dung trang web (không có robots tức là Allow: toàn bộ)
Nếu robots bị sai câu lệnh, câu lệnh không có nghĩa? Thì cũng như trên, bọ tìm kiếm vẫn sẽ hiểu câu lệnh SAI tức là Allow:
Nếu robots có dòng Disallow: / thì có sao không? Cần xóa ngay dòng này, đây có nghĩa là: Chặn toàn bộ, không index trang web. Nếu đang Top mà bị thêm dòng này, web bay hết khỏi Google luôn!
Kết luận
Robots.txt là một trong những kiến thức SEO cơ bản mà bạn cần nắm rõ, thực thi đúng. Vì đây là cốt lõi của trang web với mỗi bọ tìm kiếm. Ứng dụng file này thật linh hoạt để chặn những gì không cần thiết trên web. Nhắc đi nhắc lại rằng file này vô cùng quan trọng, nếu vô tình làm sai thì sửa lại ngay còn kịp.
Cần hỗ trợ gì comment bên dưới nhé.
— SEO Max





NHẬN TIN BÀI MỚI
Thấy bác ghé web em cũng lâu lâu, bác có muốn
- Nhận bài viết và thông tin mới ?
- Nhận Theme & Plugin miễn phí?
Đăng ký ngay nhé! Em gửi qua email cho
Thành công! Xin cảm ơn.